Model Context Protocol
AI와 세상을 잇는 새로운 표준
2025-04-01
281
8분
soaple
안녕하세요, 소플입니다.
최근 AI 업계에서 가장 화두가 되는 주제는 바로 MCP(Model Context Protocol)가 아닐까 싶습니다.
개인적으로는 미래의 AI Agent의 기능을 구현하는데 MCP가 굉장히 중요한 역할을 하게 될 거라고 생각합니다.
이번 매거진에서는 바로 이 MCP에 대한 대략적인 내용을 살펴보고, 프론트엔드 관점에서의 MCP에 대해서도 같이 살펴보도록 하겠습니다.
MCP란? 🤔
MCP는 Model Context Protocol의 약자로써, 애플리케이션이 LLM에 컨텍스트를 제공하는 방식을 표준화하는 개방형 프로토콜입니다.
쉽게 말하면, ChatGPT나 Claude 같은 LLM이 외부 데이터 소스와 상호작용할 수 있도록 만든 표준화된 방법인 것이죠.
참고로 MCP는 Claude를 만든 Anthropic에서 만든 프로토콜입니다.
공식 웹사이트에서는 MCP를 AI 애플리케이션을 위한 USB-C 포트라고 비유하고 있습니다.
우리가 USB-C 표준을 만족하는 키보드나 마우스 등의 다양한 장치들을 컴퓨터에 연결해서 사용할 수 있는 것처럼,
MCP는 MCP 표준을 만족하는 다양한 데이터 소스나 도구들을 AI에 연결해서 사용할 수 있게 해주는 것이죠.

https://modelcontextprotocol.io/introduction
MCP를 사용하면 LLM이 기존에 학습된 데이터에만 의존하지 않고, 실시간으로 다양한 외부 정보를 활용해 더 정확하고 유연한 응답을 생성할 수 있게 됩니다.
또한 기존에 LLM이 접근하지 못하는 내 컴퓨터의 파일 시스템이나 애플리케이션 등을 직접 조작할 수도 있습니다.
예를 들면, Slack 대화 기록, GitHub repository, 사용자의 로컬 문서 등의 다양한 데이터 소스를 LLM에 연결시킬 수 있습니다.
이를 통해 AI가 단순히 질문에 답변만 하는 것이 아닌, 제대로 된 AI Agent로 거듭날 수 있게 되는 것이죠.
MCP의 탄생 배경 ✨
그렇다면 MCP는 왜 탄생하게 되었을까요? 그건 바로 기존 LLM의 한계에서 출발합니다.
1. 기존 LLM의 한계
많은 분들이 아시다시피, 기존 LLM은 학습 데이터에 크게 의존합니다.
예를 들어, 2024년까지의 데이터만을 사용해서 학습된 LLM은 2025년의 최신 정보에 대해 답변을 할 수 없습니다.
그렇기 때문에 실시간으로 빠르게 변하는 날씨, 증시, 환율 등의 정보에 대해서는 제대로 된 답변을 할 수가 없었습니다.
그래서 검색엔진 등의 외부 데이터 소스를 연동해서 답변을 생성할 수 있게 하는 RAG(Retrieval-Augmented Generation) 가 각광을 받게되었죠.
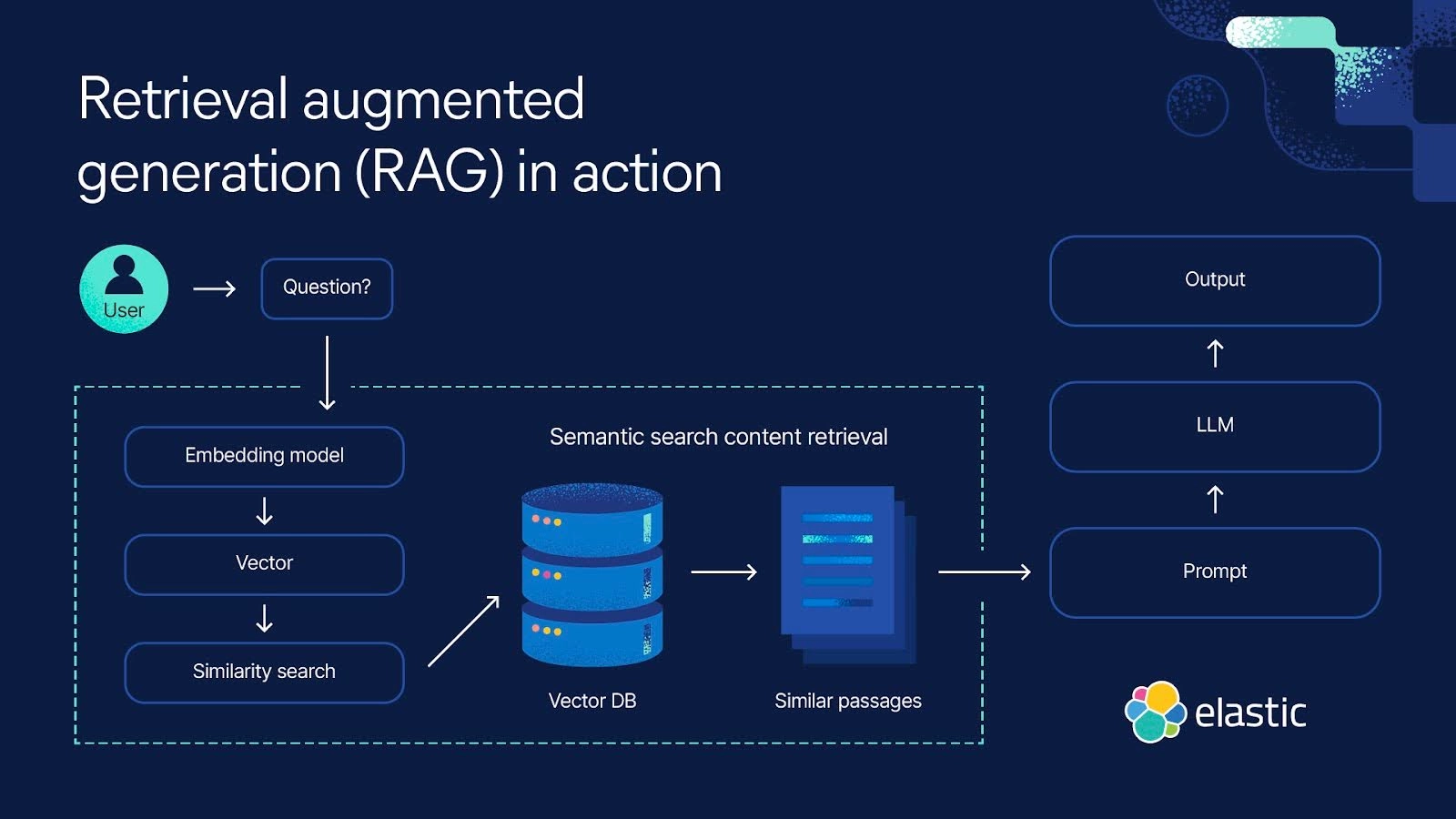
(출처: https://www.elastic.co/kr/what-is/retrieval-augmented-generation)
외부 데이터를 활용한다는 점에서는 기존에 RAG가 하던 역할과 비슷하다고 생각할 수도 있습니다.
하지만 MCP는 외부 데이터 소스 및 애플리케이션과 양방향으로 상호작용하는 것에 초점이 맞춰져 있고,
RAG는 단방향으로 응답을 생성하는데 초점이 맞춰져 있다는 차이가 있습니다.
즉, MCP가 더 광범위한 데이터 소스와 통합을 지원하는 반면, RAG는 검색 효율성과 생성 품질에 초점을 두고 있는 것이죠.
2. 데이터 연동과 확장성 문제
MCP 이전에는 각 플랫폼마다 API 구조와 데이터 형식이 다르기 때문에, 개발자가 이를 일일이 맞추는 작업을 해야만 했습니다.
예를 들어, Slack의 메시지를 가져오려면 Slack API를, GitHub 데이터를 가져오려면 GitHub API를 별도로 연동해야하는 것이죠.
하지만 이런 방식은 시간이 많이 걸리고, 새로운 데이터 소스가 추가될 때마다 동일한 형태의 작업을 반복해야 한다는 단점이 있습니다.
그 과정에서 LLM의 확장성이 굉장히 떨어지게 되었고, 자연스레 데이터 소스와 LLM 간의 연결 표준화에 대한 필요성이 대두되었습니다.
그리고 MCP의 등장으로 개발자는 더 이상 개별 API에 신경 쓰지 않고, 표준화된 방식으로 데이터를 가져올 수 있게 되었습니다.
MCP 기본 구조 🏗️
MCP의 핵심에는 클라이언트-서버 아키텍처가 있습니다.
아래 그림과 같이 하나의 Host 애플리케이션(예: Claude, IDE 등)이 MCP Protocol을 따르는 여러 개의 서버에 연결할 수 있는 구조입니다.
이를 통해, 여러 개의 데이터 소스로부터 데이터를 가져와서 더욱 더 사용자에게 맞춰진 답변을 할 수 있습니다.

(출처: https://modelcontextprotocol.io/introduction)
위 그림에서 등장하는 각 구성요소의 역할은 아래와 같습니다.
- MCP Hosts
- MCP를 통해 데이터에 접근하려는 프로그램 (예: Claude Desktop, IDE, 또는 AI 도구들)
- MCP Clients
- 서버와 1:1 연결을 유지하는 프로토콜 클라이언트
- MCP Servers
- 표준화된 Model Context Protocol를 통해 각각 특정 기능을 제공하는 프로그램
- Local Data Sources
- MCP 서버가 안전하게 접근할 수 있는 사용자의 로컬 컴퓨터 파일, 데이터베이스, 서비스 등
- Remote Services
- 인터넷을 통해 MCP 서버가 연결할 수 있는 외부 시스템
정리해보면 MCP Host가 MCP Client들을 통해 각각의 MCP Server에 요청을 보내고, 응답을 통해 전달받은 데이터들을 분석해서 종합적으로 응답을 생성해내는 것입니다.
그리고 이 과정에서 데이터 형식이 표준화되어 있기 때문에, 서로 다른 데이터 소스에서도 일관된 처리가 가능합니다.
예를 들어, 텍스트, 이미지, PDF 등 다양한 형식의 데이터를 MCP가 통합적으로 처리할 수 있는 것이죠.
MCP 핵심 컨셉 📌
다음으로는 MCP를 구성하는 핵심 컨셉들에 대해서 살펴보겠습니다.
1. Resources
Resources는 MCP Server가 MCP Client에 제공하고자 하는 모든 종류의 데이터를 나타냅니다.
데이터를 제공하지만 복잡한 연산이나 side effects를 수행하면 안된다는 점에서 REST API의 GET 엔드포인트와 유사합니다.
Resources의 예시로는 아래와 같은 것들이 있습니다.
- 파일 컨텐츠
- 데이터베이스 레코드
- API 응답
- 라이브 시스템 데이터
- 스크린샷과 이미지
- 로그 파일
그리고 Resource의 URI는 아래와 같은 형태로 정의합니다.
[protocol]://[host]/[path]
예를 들면 아래와 같은 식이죠.
file:///home/user/documents/report.pdfpostgres://database/customers/schemascreen://localhost/display1
2. Prompts
Prompts는 LLM이 MCP Server와 효과적으로 상호 작용할 수 있도록 도와주는 재사용 가능한 템플릿입니다.
Prompts는 MCP Server가 재사용 가능한 프롬프트 템플릿과 워크플로우를 정의할 수 있게 해주며,
MCP Client가 이를 사용자와 LLM에 쉽게 제공할 수 있도록 해줍니다.
아래는 Prompt의 구조를 나타낸 코드입니다.
{
name: string; // Unique identifier for the prompt
description?: string; // Human-readable description
arguments?: [ // Optional list of arguments
{
name: string; // Argument identifier
description?: string; // Argument description
required?: boolean; // Whether argument is required
}
]
}
3. Tools
Tools는 LLM이 MCP Server를 통해 실제 작업을 수행할 수 있게 해주는 도구입니다.
Resources와는 달리 Tools에서는 복잡한 연산이나 side effects를 수행할 수 있습니다.
아래는 Tool을 정의하기 위한 구조를 나타낸 코드입니다.
{
name: string; // Unique identifier for the tool
description?: string; // Human-readable description
inputSchema: { // JSON Schema for the tool's parameters
type: "object",
properties: { ... } // Tool-specific parameters
}
}
4. Sampling
Sampling은 MCP Server가 MCP Client를 통해 LLM에게 Completion 요청을 할 수 있게 해주는 기능입니다.
MCP Client가 MCP Server에 요청을 하는 것이 아니라, 역으로 MCP Server가 MCP Client에게 요청을 하는 것입니다.
아래는 MCP Server와 Client 사이에서 Sampling이 작동하는 과정을 나타낸 것입니다.
- 서버가 클라이언트에게
sampling/createMessage요청 전송 - 클라이언트가 요청을 검토하고 수정
- 클라이언트가 LLM을 통해 Sampling 수행
- 클라이언트가 completion 결과 검토
- 클라이언트가 결과를 서버로 반환
이처럼 Sampling은 MCP Server와 Client의 상호작용을 돕기 때문에, 정교한 AI Agent 동작을 구현하기 위한 핵심이라고 할 수 있습니다.
5. Roots
Roots는 MCP Server가 작동할 수 있는 경계를 정의하는 개념입니다.
MCP Client가 MCP Server에 연결할 때, 서버가 작업해야 할 URI가 바로 Root입니다.
Roots는 주로 파일 시스템 경로지만, HTTP URL을 포함한 모든 유효한 URI가 Roots가 될 수 있습니다.
아래는 Roots의 예시를 나타낸 것입니다.
file:///home/user/projects/myapp
https://api.example.com/v1
6. Transports
Transports는 MCP Client와 MCP Server 간의 통신을 위한 기반을 제공합니다.
어떻게 메시지를 보내고 받을지에 대한 기본 메커니즘을 정의하는 개념입니다.
아래 그림과 같이 MCP Client와 MCP Server 사이에 Transport Layer가 존재하게 됩니다.
Transport Layer는 MCP 프로토콜 메시지를 JSON-RPC 형식으로 변환하여 전송하고, 수신된 JSON-RPC 메시지를 다시 MCP 프로토콜 메시지로 변환하는 역할을 담당합니다.
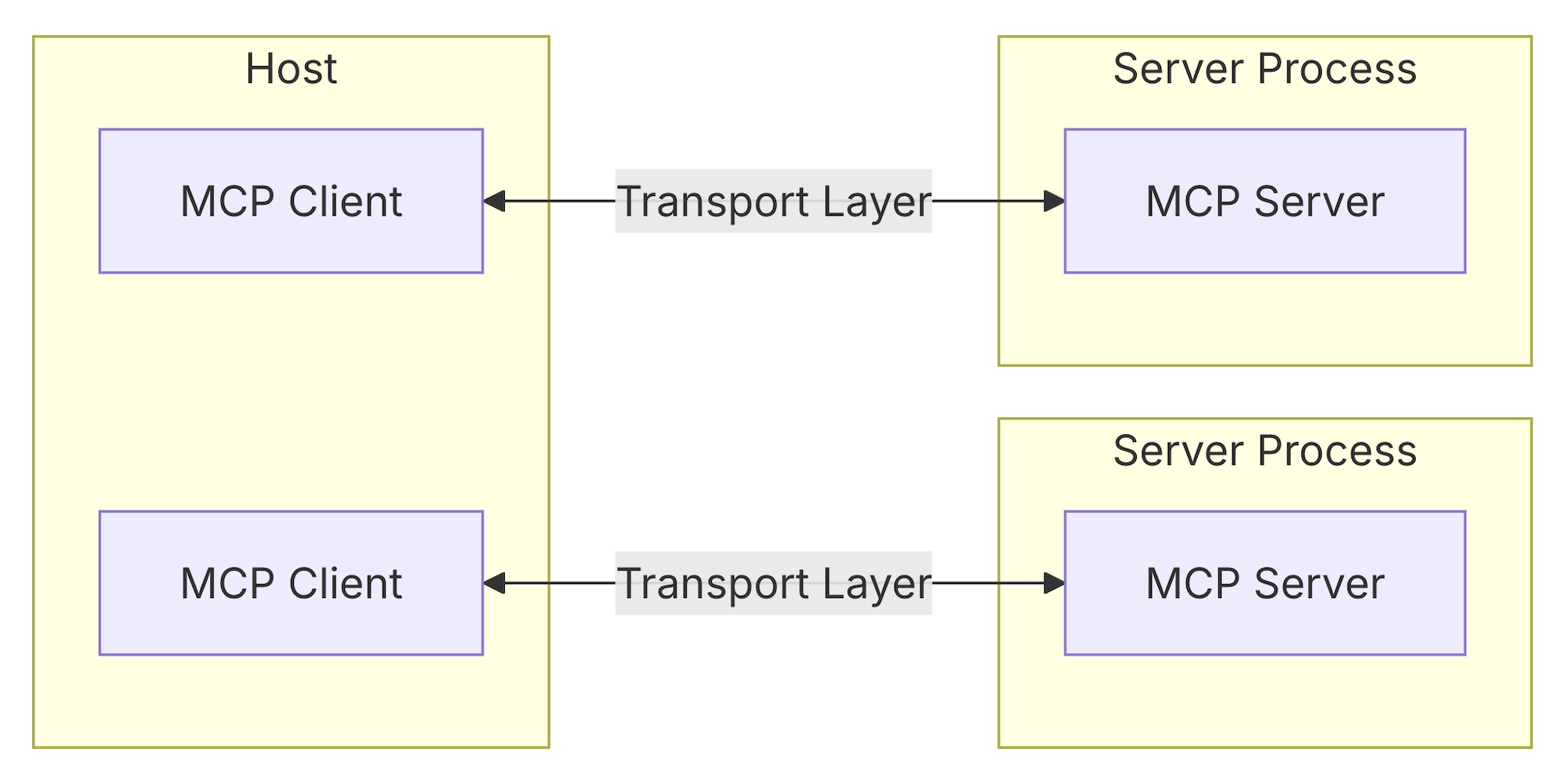
💡 MCP는 전송 형식으로 JSON-RPC 2.0을 사용합니다.
MCP의 특징과 장점 👍
그렇다면 MCP의 특징과 장점은 어떤 것들이 있을까요?
먼저 MCP의 가장 큰 특징은 오픈소스라는 것입니다.
그렇기 때문에 누구든지 아래와 같이 GitHub에서 소스코드를 볼 수 있고, 필요한 경우 Contribution을 할 수도 있습니다.

https://github.com/modelcontextprotocol
오픈소스의 가장 큰 장점은 커뮤니티 기반으로 빠르게 발전해나갈 수 있다는 점이 아닐까 싶습니다.
또한 개방형 표준이기 때문에 어떤 한 기업이 독점적인 통제를 받지 않는다는 것도 굉장히 큰 장점이라고 생각합니다.
표준화를 통해 각 플랫폼 별로 코드를 작성할 필요없이, 하나의 표준화된 코드로 모든 플랫폼에서 사용할 수 있는 것이죠.
그리고 MCP는 다양한 데이터 소스와의 연결성을 자랑합니다.
Slack에 있는 메시지, GitHub Repository에 있는 소스코드, 그리고 사용자 컴퓨터에 있는 로컬 파일 등의 모든 데이터를 참조할 수 있습니다.
이를 통해 기존 LLM의 한계를 뛰어넘게 해준다는 것도 큰 장점이라고 생각합니다.
MCP 활용 사례 🧑🏻💻
우리는 MCP를 활용해서 어떤 작업들을 할 수 있을까요?
지금부터는 대표적인 MCP 활용 사례들을 몇가지 살펴보도록 하겠습니다.
1. 실시간 코드 분석 및 수정 제안
MCP를 사용하면 LLM이 내 프로젝트 코드를 실시간으로 분석하게 만들 수 있습니다.
그리고 이를 통해 코드 자동 완성, 버그 감지, 리팩토링 제안 등을 제공할 수 있습니다.
예를 들어, MCP Client(예: VS Code)가 /src 폴더를 Root로 설정하면,
MCP Server는 해당 폴더 내 파일을 기반으로 AI가 컨텍스트를 이해하고 개발자에게 맞춤형 피드백을 제공하도록 해줍니다.
기존 Copilot과 유사한 기능을 MCP를 활용하여 직접 구현할 수 있는 것이죠.
2. 웹 기반 서비스와의 통합
MCP를 사용하면 웹 기반 서비스의 데이터를 가져와서 AI가 컨텍스트를 이해하고 답변을 하도록 만들 수 있습니다.
예를 들어, MCP Client가 https://github.com/username/repo를 Root로 설정하면,
MCP Server는 해당 GitHub repository에서 최신 커밋 내역과 이슈를 분석하고 요약 보고서를 생성하도록 만들 수 있습니다.
3. 개인화된 문서 관리 및 검색
MCP를 사용하면 개인 컴퓨터에 있는 로컬 파일이나 클라우드에 있는 문서 데이터를 통해 답변을 하도록 만들 수 있습니다.
예를 들어, MCP Client가 /documents 또는 https://drive.google.com/folder를 Root로 설정하면,
AI가 문서 내용을 분석해 질문에 대한 답변을 생성하거나 관련 파일을 추천하도록 만들 수 있습니다.
MCP 시대의 프론트엔드 개발 💻
그렇다면 앞으로 펼쳐질 MCP 시대에 프론트엔드 개발자의 역할은 어떻게 될까요?
MCP는 AI 모델과 외부 데이터 소스를 연결하는 백엔드 중심의 프로토콜이지만,
프론트엔드 개발자는 이를 활용하거나 통합된 시스템의 UI를 구현하는 데 중요한 역할을 하게 될 것이라고 생각합니다.
예를 들면, 실시간 데이터 표시를 위한 UI를 설계 및 구현하거나, 사용자가 AI와 상호작용할 수 있는 인터페이스를 구현하는 등의 업무를 하게될 것이라고 생각합니다.
MCP가 AI와 데이터를 연결하는 중간 다리라면, 프론트엔드 개발자는 그 결과를 사용자에게 보여주고 실질적으로 상호작용할 수 있게 만드는 역할을 담당하는 것이죠.
또한 앞으로는 새로운 웹 기반의 서비스를 개발할 때, 해당 서비스가 MCP 친화적인지 여부가 서비스 활성화를 결정짓는데 굉장히 큰 역할을 할 것이라고 생각합니다.
미래 AI 시대에는 AI와 소통이 잘 되는 서비스일수록 더 많은 사용자들이 사용할 것이기 때문이죠.
그런 관점에서 앞으로는 프론트엔드 개발자들도 MCP에 대한 이해나 구현 경험이 필요하게 되지 않을까 생각합니다.
🔗 참고 링크
- https://modelcontextprotocol.io/
- https://github.com/modelcontextprotocol
- https://github.com/modelcontextprotocol/typescript-sdk
이번 매거진에서는 요즘 화두인 Model Context Protocol에 대해 살펴보았습니다.
개인적으로는 MCP를 기점으로 새로운 AI Agent 시대가 열리지 않을까 생각이 드는데요,
여러분들도 글로만 읽지마시고 직접 MCP를 사용해서 재미있는 작업들을 한 번 해보면 좋지 않을까 싶습니다.
저는 다음에 또 유익한 글로 찾아뵙겠습니다!
지금까지 소플이었습니다. 감사합니다 😀
지금 가입하고 프론트엔드 개발 관련 매거진을 이메일로 받아보세요!